Решение задачи распределения реляционной базы данных.
Новосельский Вениамин
Борисович,
аспирант Санкт-Петербургского Государственного Университета Информационных
Технологий, Механики и Оптики.
Технологии баз данных (БД) в настоящее время используются практически во всех организациях. Все большую значимость приобретают процессы децентрализации, требующие создания приложений, доступ к которым осуществляется из различных географических местоположений. Увеличиваются требования к оперативности и достоверности информации. Задачи информационной интеграции БД и проектирования географически распределенных БД (РаБД) являются наиболее актуальными для разработчиков программного обеспечения в течение почти трех десятилетий.
Большинство авторов под проектированием РаБД понимают фрагментацию и размещение, т.е. разбиение БД на фрагменты и принятие решения о том, где будут храниться эти фрагменты. Однако, проектирование схем фрагментации и размещения отношений основывается на информации о способах и методах использования РаБД. Методы использования зависят от стратегии исполнения запросов, которая в свою очередь должна учитывать схемы фрагментации и размещения. Следовательно, проектирование фрагментации, размещения и стратегии исполнения запросов должны производиться одновременно. Таким образом, задачу проектирования РаБД следует формулировать так: для данной логической схемы БД, множества запросов и конфигурации вычислительной сети (ВС) описать схему фрагментации, схему размещения фрагментов и стратегии исполнения каждого запроса таким образом, чтобы оптимизировать целевую функцию.
Все три задачи, входящие в процесс проектирования РаБД, NP-полные [1, 2], т.е. с ростом размерности задач их вычислительная сложность растет экспоненциально. Во многих работах [3-5] отмечается, что для решения задач кластеризации и компоновки наиболее успешно применяются генетические алгоритмы (ГА). Помимо NP-полноты, задачи проектирования РаБД обладают свойством взаимозависимости, т.е. входными данными для следующей задачи является решение предыдущей. Таким образом, для получения проекта РаБД, близкого к оптимальному, целесообразно применять вложенные ГА.
В разработанном автором методе для каждой хромосомы из сформированного поколения схем фрагментации и размещения запускается вложенный ГА, направленный на получение оптимальной стратегии исполнения запросов. Хромосомы вложенного алгоритма сформированы из решений, принимаемых при исполнении запроса. Комбинация хромосом из внешнего и вложенного алгоритмов полностью описывают проект РаБД.
Сначала необходимо сформировать пространство поиска схем фрагментации, размещения и стратегии исполнения запросов, затем схемы должны быть представлены в виде хромосом. Пространство поиска схемы фрагментации формируется разбиением отношений на минимальные, не делимые далее, фрагменты. Для получения такого набора фрагментов для каждого отношения R на основании транзакций определяется набор минтерм предикатов и группы атрибутов. Причем предикаты описывают применение горизонтальной фрагментации, а группы атрибутов – вертикальной.
Схема размещения кодируется бинарной матрицей D, строками которой являются узлы ВС, а столбцами – сформированный набор фрагментов. Единица в ячейке матрицы Di,j означает наличие фрагмента i в узле j. Структура матрицы приведена в таблице 1.
Таблица 1.
Пример схемы фрагментации и размещения.
|
Узлы \ фрагменты |
Отношение 1 |
Отношение 2 |
||||||
|
Атрибуты |
Предикаты |
Атрибуты |
Предикаты |
|||||
|
Атр1 |
Атр2 |
Пред1 |
Пред2 |
Атр1 |
Атр2 |
Пред1 |
Пред2 |
|
|
Узел1 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
|
Узел2 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
Для удовлетворения свойства полноты схемы размещения каждый фрагмент должен находиться хотя бы в одном узле (в каждой колонке должна быть хотя бы одна единица).
При исполнении реляционного запроса необходимо принять следующие решения:
1. В какой последовательности производить операции соединения.
2. В каком узле производить операцию соединения.
3. Применять ли технику semi-join [6] при соединении. Semi-join может применяться при соединении отношений, находящихся на разных узлах. Пусть отношение A находится в узле 1 и отношение B находится в узле 2. Идея semi-join состоит в отправке на узел 2 колонок отношения A, по которым осуществляется соединение, нахождение и отправка на узел 1 только тех записей из B, которые удовлетворяют условию соединения. Как правило, техника semi-join позволяет получить выигрыш в случае, когда отношение B содержит «тяжелые» колонки, например мультимедийную информацию.
4. Применять ли технику double-pipelined hash join [7] при соединении. Идея double-pipelined hash-join состоит в формировании двух хэш-таблиц Ha и Hb, после чего записи из A и B обрабатываются по одной в каждый момент времени. Для записи из A в Hb ищутся соответствующие записи, после чего запись из A и найденные записи из B возвращаются как результаты соединения и запись из A помещается в хэш-таблицу Ha. Далее берется запись из B и обрабатывается аналогичным образом.
5. Какие узлы, имеющие необходимые фрагменты, использовать при внутриоператорном параллелизме.
Функцией приспособленности вложенного алгоритма является критерий оптимальности РаБД. Для всех запросов производится расчет уменьшения времени исполнения за счет применения внутриоператорного параллелизма и коэффициентов использования ресурсов.
После останова вложенного алгоритма значение функции приспособленности лучшей хромосомы используется как оценка функции приспособленности внешнего алгоритма. Критерием останова алгоритмов является cхождение популяции.
Для оценки качества предложенного алгоритма был произведен эксперимент, в котором решения, найденные с помощью ГА, сравнивались с оптимальными решениями. Использовался следующий критерий эффективности:
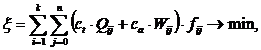
где k – количество узлов ВС; n – количество запросов; fij – частота возникновения j-го запроса в i-ом узле; Qij – временной коэффициент j-ого запроса, порожденного в i-ом узле; Wij – коэффициент использования ресурсов при обработке j-го запроса, порожденного в i-ом узле; ct и ca – коэффициенты важности времени ответа и готовности транзакции, лежат в пределах [0..1]. Значения коэффициентов определяются проектировщиком на основании требований к РаБД.
Временной коэффициент j-ого запроса определяется как Qij=Tijd/Tijl, т.е. равен отношению времени ответа на запрос, исполненного в РаБД, к расчетному времени ответа на запрос, исполненного локально в узле i, при условии наличия в узле всех необходимых фрагментов. Коэффициент использования ресурсов равен сумме коэффициентов использования центрального процессора и внешнего запоминающего устройства узлов, вовлеченных в операцию, и коэффициента использования сетевых ресурсов.
Эксперимент проводился для следующей конфигурации: ВС состоит из 3-х узлов, равноудаленных друг от друга; логическая схема БД имеет 2 отношения; производится 3 запроса на выборку и 2 запроса на обновление данных, которые формируют 4 группы атрибутов и 5 предикатов.
Измерения показали, что
оптимальные значения для параметров ГА лежат в пределах, приведенных в таблице
2. Запуск алгоритма с другими
значениями параметров ухудшает качество результата или увеличивает время
работы.
Таблица 2.
Оптимальные параметры генетических
алгоритмов.
|
|
Внешний алгоритм |
Внутренний алгоритм |
|
Размер популяции |
25¸35 |
100¸110 |
|
Вероятность скрещивания |
0.45¸0.70 |
0.55¸0.65 |
|
Вероятность мутации |
0.0075¸0.0100 |
0.0075¸0.0100 |
Схождение популяций, при котором 90% лучших особей имеют расхождение в значении функции приспособленности не более 10%, наблюдалось примерно после 500¸700 поколений внешнего ГА и 2500¸3000 поколений внутреннего ГА. Отметим, что для различных значений ct и ca ГА удалось найти оптимальное решение, полученное полным перебором. Кроме этого, с увеличением пространства возможных решений (количества фрагментов и узлов ВС) время работы ГА увеличивается квадратично, в то время как поиск оптимального решения полным перебором растет экспоненциально.
В дальнейшем возможно расширение модели РаБД за счет интеграции различных способов распространения обновлений [8], что позволит проектировщику приблизить модель к реальной вычислительной среде. Также необходимо дальнейшее исследование зависимости скорости схождения популяций от параметров ГА.
Литература.
1. Ahmad
I., Karlapalem K., Kwok Y.K., et al. Evolutionary Algorithms for Allocating
Data in Distributed Database Systems // Distributed and Parallel Databases. –
2002. – Vol. 11, N1. – pp. 5–32.
2. Apers
P.M.G. Data allocation in distributed database systems // ACM Transactions on
Database Systems. – 1988. – Vol. 13, N3. – pp. 263–304.
3. Rho
S., March S.T. Optimizing distributed join queries: A genetic algorithm
approach // Annals of Operations Research. – 1997. – Vol. 71, N0. – pp.
199-228.
4. Wang
J.-C., Horng J.-T., Hsu Y.-M., et al. A genetic algorithm for set query
optimization in distributed database systems // IEEE International Conference
on Systems, Man, and Cybernetics. – 1996. – pp. 1977-1982.
5. Норенков И.П. Эвристики и их комбинации в генетических методах дискретной оптимизации // Информационные технологии. – 1999. – N1. – с. 2–7. – ISSN 1994-0408.
6. Bernstein
P.A., Goodman N., Wong E., et al. Query processing in a system for distributed
databases (SDD-1) // ACM Trans. Database Syst. – 1981. – Vol. 6, N4. – pp.
602–625. – ISSN 0362-5915.
7. Wilschut
A.N., Apers P.M.G. Dataflow query execution in a parallel main-memory
environment // Distrib. Parallel Databases. – 1993. – Vol. 1, N1. – pp.
103–128. – ISSN 0926-8782.
8. Стеен М., Тенебаум Э. Распределенные системы. Принципы и парадигмы // СПб: Питер, 2003. – 880 с.
Поступила в редакцию 28.04.2008 г.