Эффективное представление видеоданных
оптико-электронных средств траекторных измерений.
Бабаев
Антон Александрович,
аспирант кафедры Радиосистемы Новгородского
Государственного
Университета имени Ярослава Мудрого,
инженер-программист.
1. Введение. Постановка задачи.
В настоящее время для траекторных измерений
используются оптико-электронные средства на основе цифровых видеокамер с
высоким разрешением и большой частотой кадров. При этом объёмы и скорость
поступления информации возрастают настолько, что даже использование современной элементной базы не позволяет без
потерь обрабатывать видеоданные в реальном времени. Известны методы, которые
можно использовать для эффективного представления видеоданных без потерь [1-9].
Наиболее приемлемыми для траекторных измерений являются алгоритмы с
предсказателем MED [10], эффективность которых,
однако, тоже недостаточна. Вопросам поиска более быстродействующих алгоритмов
посвящена настоящая работа.
2. Основные определения.
Структура типовой оптико-электронной системы
(ОЭС) и её модели рассматривалась в [11,12,13]
и может быть представлена в виде: рисунок 1.

Рис. 1.
Модель ОЭС вычисления траекторий
объектов.
1 – видеопоток, 2 - оптическая система, 3
- приемник излучения, 4 - электронный тракт, 5 - кодер видеоданных, 6 – регистратор
видеоданных, 7 -обработчик информации, 8 - получатель информации.
К критериям эффективности представления
видеоданных оптико-электронных средств траекторных измерений можно отнести:
степень сжатия, скорость преобразований, объемы памяти, необходимые для преобразований,
ошибки в вычислении траектории. При этом для нас важно получение данных без
потерь.
Эффективным представлением видеоданных будем считать представление без потерь информации
с максимально возможной степенью сжатия в реальном времени.
3. Способы решения поставленной
задачи.
На
сегодняшний день существует большое количество методов, алгоритмов и стандартов
представления видеоданных[1-9,14,15,16]. Их можно разделить на три типа: реализующие
сжатие без потерь, сжатие без потерь качества (является необратимым), сжатие с
потерями (является необратимым).
В силу того, что скорости получения данных в современных
оптико-электронных средствах траекторных измерений могут достигать сотен мегабайт
в секунду и более, то не будем рассматривать методы, использующие межкадровое
кодирование. Так как сжатие без потерь качества и сжатие с потерями являются
необратимыми и влияют на точность определения координат, в данной работе они тоже
не рассматриваются.
Среди методов без потерь выделяют: статистические,
словарные, контекстные, с предсказанием, прогрессивные [8,9,17,18]. Наиболее
удовлетворяют рассмотренным критериям: контекстные, с предсказанием, прогрессивные.
Контекстно-зависимые
методы. При использовании такого
метода выбор информационной модели в каждый момент времени осуществляется на основе
значения некоторого контекста, который формируется из элементов уже
обработанной информационной выборки. Для каждой модели хранится статистическая
информация о появлении различных символов информационного алфавита в контексте,
соответствующем данной модели. На основе этой информации формируется
распределение вероятностных оценок появления символов на выходе источника,
которое служит основой для генерации кода[9].
Методы
с предсказанием. Методы с
предсказанием используют предсказатели, на основании которых делается прогноз о
значении текущего пикселя, затем значение ошибки предсказания подаётся в универсальный
компрессор для кодирования. Принцип работы методов с предсказанием отражён на структурной
схеме Рисунок 2.

Рис. 2.
Обобщенная структурная схема методов с
предсказанием.
X – входные
данные, X’ –
предсказанное значение, E – ошибка
предсказания, Y – выходной
поток после кодирования ошибки предсказания универсальным компрессором.
Методы
прогрессивного сжатия. Прогрессивное
сжатие (в том числе Wavelet
преобразование), вначале преобразует рисунок в целом, с небольшим разрешением,
а затем преобразует тончайшие детали в соответствии с необходимым разрешением.
Прогрессивные методы поддерживают многократные уровни детализации. Невысокая
аппроксимация модели доступна сразу, с последующим увеличением информации о
деталях.
Алгоритмы без потерь. Наиболее распространённые алгоритмы сжатия
отдельных кадров и изображений: JPEG-LS[3], LOCO-I [1,2], CALIC [5]. JPEG-LS и LOCO-I используют
предсказатель MED, а CALIC использует предсказатель GAP.
4. Решение поставленной задачи.
4.1.
Описание предлагаемого алгоритма.
В работе предложен адаптивный медианный алгоритм
без потерь ALMA (Adaptive Lossless Median Algorithm). Данный алгоритм состоит из блока
реализующего предсказатель Lossless Median Predictor (LMP), блока вычисления ошибки предсказания,
блока переноса предсказанного значения в диапазон неотрицательных чисел, блока
кодирования. Структура алгоритма представлена на рисунке 3.

Рис. 3.
Структура предложенного алгоритма ALMA.
X - входной
поток, P -
предсказанное значение яркости текущего пикселя, E - ошибка предсказания яркости текущего пикселя, M - ошибка предсказания яркости текущего пикселя
перенесённая в диапазон неотрицательных чисел, Y - выходной
поток после этапа кодирования.
Если обозначить близлежащие пиксели как
показано на рисунке 4.,
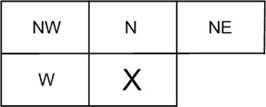
Рис. 4.
Близлежащие пиксели.
то алгоритм предсказателя (LMP) записать в виде:
IF ![]() THEN
THEN
IF ![]() THEN
THEN
IF ![]() THEN
THEN![]()
ELSE
![]() END IF;
END IF;
ELSIF ![]() THEN
THEN
IF ![]() THEN
THEN![]()
ELSE
![]() END IF;
END IF;
ELSE
IF ![]() THEN
THEN ![]()
ELSE ![]() END IF;
END IF;
END IF;
ELSE
IF ![]() THEN
THEN
IF ![]() THEN
THEN ![]()
ELSE
![]() END IF;
END IF;
ELSIF ![]() THEN
THEN
IF ![]() THEN
THEN ![]()
ELSE ![]() END IF;
END IF;
ELSE
IF ![]() THEN
THEN ![]()
ELSE ![]() END IF;
END IF;
END IF;
END IF;
Где ![]() ,
,![]() ,
,![]() ,
,![]() - экспериментально полученные весовые коэффициенты, максимизирующие
степень сжатия, k –
порядковый номер участка алгоритма.
- экспериментально полученные весовые коэффициенты, максимизирующие
степень сжатия, k –
порядковый номер участка алгоритма.
Таблица 1.
Экспериментально
полученные весовые коэффициенты ![]() ,
,![]() ,
,![]() ,
,![]() максимизирующие степень сжатия.
максимизирующие степень сжатия.
|
Индекс k |
Условие |
|
|
|
|
|
1 |
N>=W, NW>=N, N<=NE |
-1/2 |
1 |
1/4 |
1/4 |
|
2 |
N>=W, NW>=N, N>NE |
0 |
1 |
0 |
0 |
|
3 |
N>=W, NW<=W, N<=NE |
1 |
3/8 |
-3/8 |
0 |
|
4 |
N>=W, NW<=W, N>NE |
7/8 |
-1/8 |
1/8 |
1/8 |
|
5 |
N>=W, NW>W, N<=NE |
1 |
1 |
-1 |
0 |
|
6 |
N>=W, NW>W, N>NE |
1 |
1 |
-1 |
0 |
|
7 |
N<W, NW>=W, N<=NE |
7/8 |
-1/4 |
1/4 |
1/8 |
|
8 |
N<W, NW>=W, N>NE |
1 |
1/4 |
-1/4 |
0 |
|
9 |
N<W, NW<=N, N<=NE |
3/8 |
1 |
-1/4 |
-1/8 |
|
10 |
N<W, NW<=N, N>NE |
-3/8 |
1 |
1/8 |
1/4 |
|
11 |
N<W, NW>N, N<=NE |
1 |
1 |
-1 |
0 |
|
12 |
N<W, NW>N, N>NE |
1 |
7/8 |
-7/8 |
0 |
Вслед за этапом предсказания в предлагаемом алгоритме следует блок вычисления ошибки предсказания. Ошибка предсказания вычисляется по следующей формуле
![]() , (1)
, (1)
где X – текущее значение во входном потоке, P - предсказанное значение яркости текущего пикселя, E - ошибка предсказания яркости текущего пикселя.
Затем следует блок переноса предсказанного значения в диапазон неотрицательных чисел. Перенос осуществляется по следующей формуле:
![]() , (2)
, (2)
где M - ошибка предсказания яркости текущего пикселя перенесённая в диапазон неотрицательных чисел, E - ошибка предсказания яркости текущего пикселя.
Далее на этапе кодирования предлагается объединение соседних ошибок предсказания и получение после объединения 18 разрядных данных. Такая реализация кодирования позволяет уменьшить в 2 раза количество операций связанных с кодированием, а также уменьшает энтропию на несколько процентов, что приводит к увеличению максимально возможной степени сжатия.
Предлагаемый в работе принцип объединения поясняет рисунок 5.
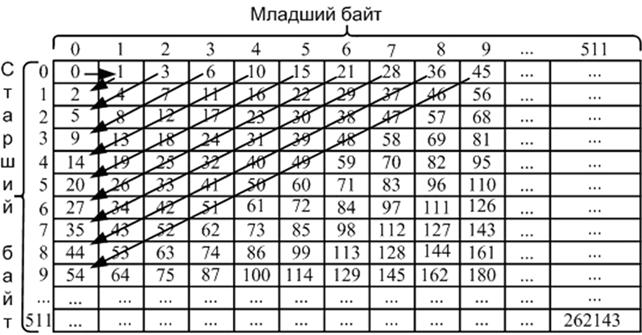
Рис. 5.
Принцип объединения соседних значений
ошибок предсказания в пары.
На рисунке 5 номер строки соответствует значению старшего байта, номер столбца – младшему байту. Вычисление значений ячеек таблицы производится по порядку, показанному стрелками.
После этапа вычисления ошибки предсказания нам потребовалось 9 бит для хранения значений, а после объединения соседних ошибок предсказания нам требуется уже 18 разрядов и диапазон возможных значений расширяется с [0,511] до [0, 262143]. Для хранения всех частот встречаемости символов потребуется 262144 18-ти разрядных слов (4718592 бит).
Исследования показали, что для реальных изображений большинство значений ошибок предсказания после объединения находится в первых сотнях диапазона [0, 262143]. Ввиду такой особенности предлагается операцию объединения осуществлять с использованием двух таблиц. Первая таблица используется для вычисления наиболее встречаемых значений и представляет двумерный массив, индексами которого служат значения ошибок предсказания, входящие в объединяемое слово. Размер первой таблицы предлагается 1024 слова. Вторая таблица служит для вычисления маловероятных значений и чтобы не тратить большое количество памяти предлагается использовать одномерный массив, представляющий продолжение первого столбца первой таблицы. Так как размер столбца первой таблицы равен 32 то для того, чтобы вычислить значение для любой пары, необходима вторая таблица размером 1024-32=992 слов. Для пояснения принципа вычисления значений с использованием двух таблиц обозначим старшие 9 разрядов пары перед объединением за x, младшие за y, тогда номер текущей диагонали d = x+y. Любая пара после объединения может быть представлена числом следующим способом:
IF ((x<32)&&(y<32)) THEN
Таблица1(x,y)
ELSE
Таблица2(x+y)-y
Значения представляющие пары предложено кодировать кодами Голомба. При этом распределение ошибок предсказания является геометрическим, о значении параметра m кода Голомба судим только по частоте встречаемости комбинации цифр «00». То есть, если встречается другая комбинация, отличная от «00», то используем уже известное нам значение m, рассчитанное для «00».
Введём следующие обозначения: Unary – унарный код, Bin – бинарный код, k – параметр кода Голомба (длина бинарного кода), k0 – предшествующее значение параметра k.
Параметр k есть ни что иное как:
![]() . (3)
. (3)
При кодировании изображения (кадра) параметр вычисляется адаптивно, следовательно значение k является переменной величиной.
Для увеличения эффективности кодирования следует добавить:
if (Unary > 2) k = k + 2;
else
k = k0;
То есть, если встречается унарный код длиной больше 2, действуем из предположения, что следующий унарный код будет не меньшей величиной и увеличиваем значение параметра к для следующего кодируемого значения. Такой подход позволяет уменьшать очень длинные унарные коды. Также в алгоритме используется лимитирование унарных кодов. Оба использованных в алгоритме подхода позволяют избегать очень длинный кодов. В предлагаемом алгоритме предельная длина унарных кодов равна 9.
4.2. Исследование предлагаемого алгоритма.
Из таблицы 1 следует, что максимальная степень сжатия наблюдается при условии:
![]() (3)
(3)
Это позволяет более просто осуществлять динамическую настройку алгоритма.
Для сравнения предложенный предсказатель LMP опробован как на стандартном тестовом наборе, так и видеоданных полученных с помощью оптико-электронных средств траекторных измерений. Для стандартного тестового набора ISO/IEC 10918-1 предложенный предсказатель показал результаты на 1,7% лучше, чем MED, но несколько хуже, чем GAP (на 0,3%). Для тестовых видеопоследовательностей, составленных из данных полученных от реальных оптико-электронных систем траекторных измерений предлагаемый LMP дал результат с точки зрения степени сжатия на 1,5% выше.
Предложенный алгоритм ALMA был опробован как на стандартном тестовом наборе ISO/IEC 10918-1, так и на видеоданных оптико-электронных средств траекторных измерений. Для изображений входящих в тестовый набор ISO/IEC 10918-1 ALMA уступил в степени сжатия JPEG-LS от 7% и больше, CALIC 10% и больше. Для тестовых видеоданных оптико-электронных средств (ОЭС) траекторных измерений величина степени сжатия для ALMA 2,1 и выше. Зато по скорости ALMA превзошёл JPEG-LS более чем 2 раза, CALIC более чем 6,5 раз. Количество операций на один байт для тестового набора ISO/IEC 10918-1 в предлагаемом алгоритме составляет 24 опер/байт, JPEG-LS – 49 опер/байт, CALIC – 157 опер/байт.
Далее в таблицах 3-9 представлены вычислительные характеристики отдельных блоков рассматриваемых различных алгоритмов.
Таблица 3.
Количество операций в блоке предсказания.
|
Операции |
JPEG-LS(MED) |
CALIC(GAP) |
ALMA(LMP) |
|
Проверок условий |
3 |
7 |
4 |
|
Сумм./выч. |
2 |
14 |
3 |
|
Взятие по модулю |
- |
6 |
- |
|
Умнож. |
- |
1 |
2 |
|
Сдвиг. |
- |
3 |
4 |
Как следует из таблицы 3 для MED количество ветвлений (условий) может составлять 3, для LMP - 4, для GAP – 7 ветвлений. Сумматоров/вычитателей для MED – максимум 2, LMP – максимум 3, GAP – максимум 14. Взятие по модулю в MED и LMP отсутствует, в GAP – 6. Умножений в MED не используется, в LMP – максимум 2, GAP – максимум 1. При этом следует отметить, что предложенный предсказатель содержит деления, кратные степени двойки, что определяет простоту вычислений, тем более, наиболее подходящая реализация для решения с его помощью задачи эффективного представления видеоданных оптико-электронных средств траекторных измерений лучше всего решается при реализации предсказателя на программируемых логических интегральных схемах (ПЛИС).
Таблица 4.
Количество операций в блоке преобразования
предсказанного значения в неотрицательное число.
|
Операции |
JPEG-LS |
CALIC |
|
|
Проверок условий |
2 |
3 |
- |
|
Деление |
- |
1 |
- |
|
Сумм./выч. |
1 |
3 |
- |
|
Сдвиг. |
- |
1 |
- |
Таблица 5.
Количество операций в блоке вычисления
ошибки предсказания.
|
Количество операций |
JPEG-LS |
CALIC |
|
|
Сумм./выч. |
1 |
1 |
1 |
|
Умнож. |
1 |
- |
- |
Таблица 6.
Количество операций в блоке
корректировки ошибки предсказания.
|
Операции |
JPEG-LS |
CALIC |
|
|
Проверок условий |
6 |
11 |
- |
|
Сумм./выч. |
12 |
6 |
- |
|
Взятие по модулю |
- |
2 |
- |
|
Умнож. |
2 |
- |
- |
|
Сдвиг. |
4 |
4 |
- |
|
2 ИЛИ |
|
8 |
|
Таблица 7.
Использование памяти.
|
JPEG-LS |
CALIC |
|
|
2265 слов |
1024 слова |
1024+992=2016 слова |
Таблица 8.
Количество операций в блоке переноса
ошибок предсказания в диапазон неотрицательных чисел.
|
Операции |
JPEG-LS |
CALIC |
|
|
Проверок условий |
3+Max9 |
5 |
1 |
|
Сумм./выч. |
4+Max9 |
6 |
1 |
|
Взятие по модулю |
- |
1 |
- |
|
Умнож. |
2 |
2 |
- |
|
Сдвиг. |
2+Max9 |
2 |
1 |
|
Цикл |
Max 9 |
- |
- |
|
Арифетическое И |
1 |
- |
- |
5. Выводы.
В работе предложен алгоритм, являющийся более эффективным с точки зрения производительности и немного проигрывающий известным в степени сжатия.
Литература.
1. Weinberger M. J., Seroussi G.,
and Sapiro G., ‘LOCO-I: A low complexity, context-based, lossless image
compression algorithm,’ Proceedings Data Compression Conference, Snowbird,
2. Weinberger M. J., Seroussi G.,
Sapiro G. The LOCO-I Lossless Image Compression Algorithm: Principles and
Standardization into JPEG-LS // IEEE Trans. on Image Processing. - 2000. - Vol.
9, №. 8. pp. 1309 - 1324.
3. ISO/IEC 14495, ITU T.87,
Information technology – Lossless and near-lossless compression of continuous-tone
still images (JPEG-LS), 1999.
4. Wu X., Memon N. D. Context-Based,
Adaptive, Lossless Image Coding // IEEE Trans. On Communications. - 1997. -
Vol. 45, №. 4. pp. 437 - 444.
5. Wu X., and Memon N.,
Context-Based Lossless Interband Compression-Extending CALIC. IEEE Transactions
on Image Processing, Vol. 9, № 6, June 2000, pp. 994-10001.
6. ISO/IEC / JTC 1/SC 29/WG 1
Information Technology – JPEG 2000 Image Coding System, ISO/IEC 15444.
7. ISO/IEC / JTC 1/SC 29/WG 10
Information Technology - Digital Compression and Coding of Continuous-Tone
Still Images, ISO/IEC 10918.
8. Семенюк В.В. Экономное кодирование дискретной информации. – СПб.: СПбГИТМО (ТУ), 2001. – 115 с.
9. Семенюк В.В. Вероятностные методы экономного кодирования видеоинформации. Дис.к.т.н.: 05.13.13 –СП., 2004.
10.Бабаев А.А. Исследование и реализация эффективного представления видеоинформации без потерь качества в траекторных измерениях. Труды РНТОРЭС имени А.С.Попова, Серия: Цифровая обработка сигналов и её применение, Выпуск VIII, -М, 2006.
11.Малинин В.В. Моделирование и оптимизация оптико-электронных приборов с фотоприемными матрицами. –Н.: НАУКА, 2005.
12.Тарасов В.В., Якушенков Ю.Г. Инфракрасные системы «смотрящего типа» -М.: ЛОГОС, 2004.
13.Якушенков Ю.Г. Теория и расчет оптико-электронных приборов – М. ЛОГОС, 2004.
14. ISO/IEC JTC 1/SC 29/WG 11 and
ITU-T SG 16 Q.6 Study of Final Committee Draft of Joint Video Specification,
ITU-T Rec. H.264 / ISO/IEC 14496-10 AVC, JVT-F100, Dec., 2002.
15.ITU-T SG 16 Video Codec for
Audiovisual Services at px64 kbits, ITU-T Recommendation H.261.
16. ITU-T SG 16 Video coding for low
bit rate communication, ITU-T Recommendation H.263.
17.Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео: -М.: ДИАЛОГ-МИФИ, 2003.-384с.
18. Добеши И. Десять лекций по вейвлетам: пер. с англ. –М.: НИИ «Регулярная и хаотическая динамика», 2004.
Поступила в редакцию 17.03.2008 г.