Алгоритмы ранжирования веб-страниц в Интернете
Нгуен Тхи Тху Ань
Nguyen Thi Thuy Anh
Faculty of Management Information System, Banking Academy, Hanoi, Vietnam.
Email: anhnt.mis@gmail.com.
Для поиска информации в сети Интернет необходима служба, позволяющая выбрать нужные документы из множества опубликованных. Наиболее проработана на современном этапе выборка текстовых документов и на текущий момент под поиском в сети Интернет подразумевают именно текстовый поиск. Предоставляющие подобные услуги службы называются поисковыми системами. Для своей работы они требуют предварительного анализа всех текстовых документов сети. Задачу можно сформулировать как задачу выбора и ранжирования альтернатив из существующего множества.
Генерация альтернатив – тривиальный процесс. Документы в сети Интернет имеют ссылки друг на друга.
Более сложным вопросом является формулирование граничных условий. При выборке страниц из доступного множества нужно отсечь варианты, не относящиеся к поисковому запросу. Запрос содержит лексемы, которые должны присутствовать в анализируемых документах, чтобы документ соответствовал ему.
Еще более сложным вопросом является формулирование критериев релевантности документа относительно поискового запроса. По сути, поисковые системы выполняют выборку и сортировку доступных страниц на основе одной цели – «соответствие документа поисковому запросу». Цель формируется нечетко и в существующих поисковых системах совершенно по-разному. При этом он является совокупным критерием, учитывающим частоту появления лексем в тексте, их группировку и последовательность, а также вес разных частей текста.
Наиболее существенное отличие процессов ранжирования документов в поисковых системах от ранжирования альтернатив в системах поддержки принятия решения (СППР) кроется в необходимости обрабатывать громадное число документов (альтернатив с точки зрения СППР). Процесс обработки заключается в просматривании и подготовке к оценке документов. Это занимает время, сравнимое со временем, в течение которого документы модифицируется или даже перестают существовать. Кроме того, количество документов в интернете постоянно растет.
К наиболее существенным критериям оценки документов относятся следующие:
- учет по используемым ключевым словам (лексемам), посещаемость (или популярность), учет авторитетности документа на основе ссылок (ссылочное ранжирование);
- критерий ключевых слов наиболее точно позволяет анализировать соответствие запроса словам в документе. Однако, так как критерий не анализирует смысл документа, он сильно подвержен фальсификации со стороны авторов документов. Достаточно много раз в «нужных» местах текста поставить ключевое слово и документ становится лидером в рейтинге по этому критерию;
- критерий учета посещаемости лучше всего отражает понятие спрос. Но спрос важен не для всех поисковых запросов. Он подвержен моде и определенным вкусам. Если использовать только данный критерий, то информация будет предоставлена однобоко. Поисковая система, ставящая данный принцип во главу угла, становится подобной издателю глянцевых журналов. Вроде информация по теме запроса представлена, но глубина изложения и смысл в ряде случаев искажен. Для учета популярности страниц используется механизм подсчета посетителей – так называемые счетчики.
Учет авторитетности - наиболее успешный критерий на текущий момент. Его успешность подтверждается лидированием в популярности поисковых систем, использующих данный принцип в обработке документов. В литературе наиболее часто этот принцип связывают с алгоритмом ранжирования PageRank [5]. Поисковая система Google базировалась на этом алгоритме при своем зарождении.
Однако существуют и другие способы учета авторитетности, основанные на анализе ссылок. Например, индекс ТиЦ Яндекса основан на алгоритме PageRank, HITS и SALSA поддерживается поисковой системой Сlever от фирмы IBM, HillTop (или LocalScore) – патент на использование данного алгоритма принадлежит Google, BackRank – модификация алгоритма PageRank, учитывающая возможность возврата пользователя браузера к ранее просмотренной странице [6].
Алгоритмы учета авторитетности работают на принципе итеративного анализа web-графа. Web-граф представляет собой ориентированный граф, вершинами которого являются документы (web страницы), а дуги - ссылками между этими документами.
В алгоритмах PageRank и BackRank ранг вершины web-графа равен вероятности ее нахождения бродящим случайным образом по сети пользователем. Эта вероятность складывается из некоторой минимальной вероятности первого захода и из суммы вероятностей перехода на него пользователя со ссылающихся документов с учетом коэффициента затухания (этот коэффициент связан с вероятностью перехода из одного документа на другой). Причем BackRank – учитывает возможность возврата назад по пройденному пути. Первоначально вероятности неизвестны, но, решая построенную систему уравнений, можно их вычислить.
Алгоритм HITS применяется на выделенном каким-либо способом подграфе (например, подграф, содержащий только вершины с заданными ключевыми словами). Согласно модели алгоритм делит все вершины на две доли: источники («autority») и хабы («hubs») [5]. Источниками выбираются наиболее популярные ресурсы по данной тематике запроса. Они определяются с помощью счетчиков. Хабы – ресурсы, ссылающиеся на множество источников. Хабы исполняют роль миникаталогов со ссылками на вершины-источники. Расчет по HITS учитывает структуру подграфа и на основе ссылок между долями двудольного графа ранжирует вершины, как источников, так и хабов.
Алгоритм HillTop (LocalScore) еще более трудоемкий. Он требует для начала своей работы выделить в web-графе экспертные документы. Выбор осуществляется каким-либо другим алгоритмом, но из логики работы HillTop экспертный документ должен отражать смысл запроса, а не только учитывать популярность вершины и частоту употребления ключевых слов. Из этого напрашивается необходимость ручной экспертной оценки некоторых вершин графа по наиболее употребляемым поисковым запросам. Алгоритм довольно сложными вычислениями исследует ссылки, связывающие экспертные документы с другими вершинами web-графа, рассматривает текст ссылок, текст самих документов и на основе полученных данных ранжирует их.
По результатам исследования публикаций, наиболее интенсивное совершенствование алгоритмов поиска в настоящее время ведется в направлении изучения макроструктуры сети Интернет и выявлению в ней некоторых закономерностей. Это связано с более высокой релевантностью результатов работы методов, учитывающих ссылки при анализе гипертекстовых документов. Основной недостаток ссылочных методов ранжирования – высокая трудоемкость и сложность в распараллеливании процесса анализа.
Web-граф существенно отличается от сгенерированной случайным образом сети. В нем выявлено ряд закономерностей и свойств, на основе которых можно увеличить быстродействие ссылочного ранжирования. На макроскопическом уровне web-граф имеет структуру «бабочки» [3]. Ее центром является группа страниц, образующих компонент сильной связности (SCC). Также имеются страницы, ссылающиеся на центральную группу (IN), страницы на которые ссылается центральная группа (OUT), множество несвязных с ними страниц, а также «трубы» – ссылки между «крыльями» бабочки.
J. Kleinberg и D. Watts [2, 1] рассмотрели неориентированный web-граф и подтвердили наличие в нем феномена «Малого мира» (Small world phenomen), типичного для динамических социальных сетей. За исключением небольшого процента, почти все вершины такого графа достижимы из любой другой через огромный центральный компонент связности, составляющий около 90% web-графа. Это связывают с наличием неявных кибер-сообществ: групп ресурсов сходной тематики, имеющих общие «авторитетные» страницы. Двудольные клики интерпретируются как ядро подобных сообществ – они состоят из множества «фанатских» и «авторитетных» страниц, причем все страницы из первого множества ссылаются на страницы второго.
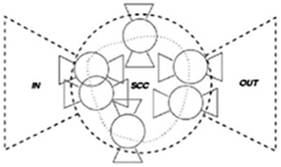
Рис. 1. Фрактальные свойства веб-графа.
S. Dill в работе [4] исследовал несколько фрактальных свойств web-графа. Изучая различные связанные группы страниц, было обнаружено подобие их структуры макроструктуре всего web-графа. Центральная часть структуры этих коллекций была названа «Тематически Объединенным Кластером» - ТОК (Thematically Unified Cluster» (TUC)).
Таким образом, эти работы свидетельствуют о возможности поиска ТОК и их выявление еще без анализа текста документов. Чтобы выявить ядро тематического кластера, нужно искать в макро web-графе тесно связанные вершины. Посвященные одной теме документы имеют свойство с течением времени объединяться через гиперсвязь с другими похожими ресурсами. Процесс разделения на тематические группы позволит распараллеливать предварительное исследование web-графа.
Выделив ТОК, можно приступить к изучению содержащихся в них документов. При этом связывающие разные ТОК ссылки игнорируются как наименее влияющие на ссылочное ранжирование внутри ТОК. Логично предположить, что наиболее часто употребляемые слова в документах из одного ТОК представляют ключевые слова по тематике данного кластера. Задача ссылочного ранжирования распадается на параллельно решаемые задачи ранжирования документов внутри разных ТОК. При этом можно использовать разные существующие методы ссылочного ранжирования. Их трудоемкость при анализе отдельных кластеров гораздо ниже за счет существенно меньшего числа вершин и дуг по сравнению со всем web графом.
Поисковый запрос определяет ключевые слова, и система может найти несколько ТОК, соответствующих поисковому запросу. В этом случае кластеры играют атомарную роль при ранжировании на основе лексем (и возможно с учетом популярности ТОК). Кластеры в такой методике анализа web графа заменяют понятие документа. Задача алгоритма на последнем шаге состоит в синтезе совокупного ранжирования всех входящих в релевантные кластеры документов. Причем ранжирование внутри кластеров уже осуществлено на предыдущем шаге. При выполнении этапа синтеза можно учесть ранее проигнорированные ссылки между кластерами. Ссылочное ранжирование можно также использовать при анализе ссылок между разными ТОК. В этом случае нужно использовать понятие авторитетности кластера.
Литература
1. Kleinberg J. «The small world phenomenon: an algorithmic perspective».
2. Watts D. «Collective dynamics of small-world networks» / D. Watts, S. Strogatz. Nature, (393):440, 1998.
3. Broder. «Graph structure in the web». / R. Kumar, F. Maghoul, P. Raghavan, S. Rajagopalan, S. Stata, A.Tomkins, and J. Wiener. In Proceedings of the 9th WWW conference, 2000.
4. Dill S. «Self-similarity in the web» / S. Dill, R. Kumar, K. McCurley, S. Rajagopalan, D. Sivakumar, and A. Tomkins. In Proceedings of the 27th VLDB Conference, 2001.
5. Kleinberg J. «Authoritative sources in a hyperlinked environment, Journal
of the ACM, 46 (1999), pp.604-632.
6. Farahat. A. «Authority rankings from HITS, PageRank, and SALSA: existence, uniqueness, and effect of initialization» / A. Farahat, T. Lofaro, J. C. Miller, G. RAE, L. A. Ward.
Поступила в редакцию 30.04.2014 г.